A copy of the Plain Talks Library also exists on the Internet Archive (IA) site. The only reason to use that site is for searching in the issues. Please read the information below about using search on the IA site. It will help make searching easier for you. You can also highlight and copy text from the issues.
The text of the issues on the IA Site is searchable. The conversion to text is not 100% accurate, but is very good on most issues. The story about how this came to be is probably not interesting to most folks but is available at the bottom of this page.
The rest of the page is information on how to search the text of all the issues in the library on the IA site. It's not particularly hard, but it is particular.
AFTER REVIEWING THE INFORMATION ABOUT HOW THE SEARCH WORKS, Click the link below and it should open up a new tab with the PT Collection on the IA site sorted in descending date order (latest first).
You can switch between that tab and here to use the instructions.
Click here to open a new tab for the GSU Plain Talks Collection on the Internet Archive site.
Some general things about searching:
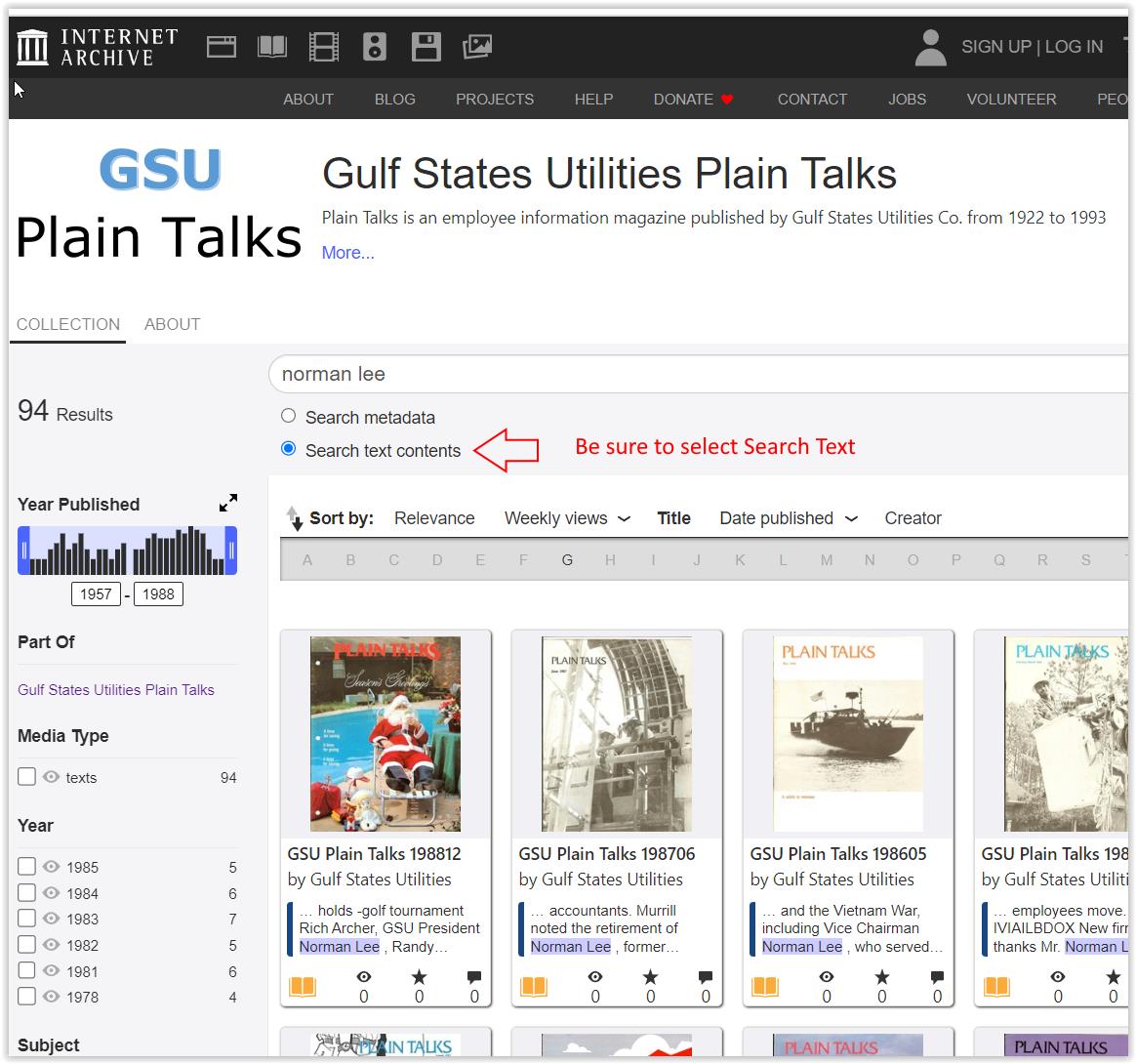
You will ALWAYS have to check the "Search Text contents" option on the left side of the screen under the search box. If you don't, you almost cetainly will get zero results.
After a search, part of the main screen looks similar to the image below. Notice that:
When in the covers (grid) view you can see the first match found and some surrounding text in each issue. There may be more than one match...
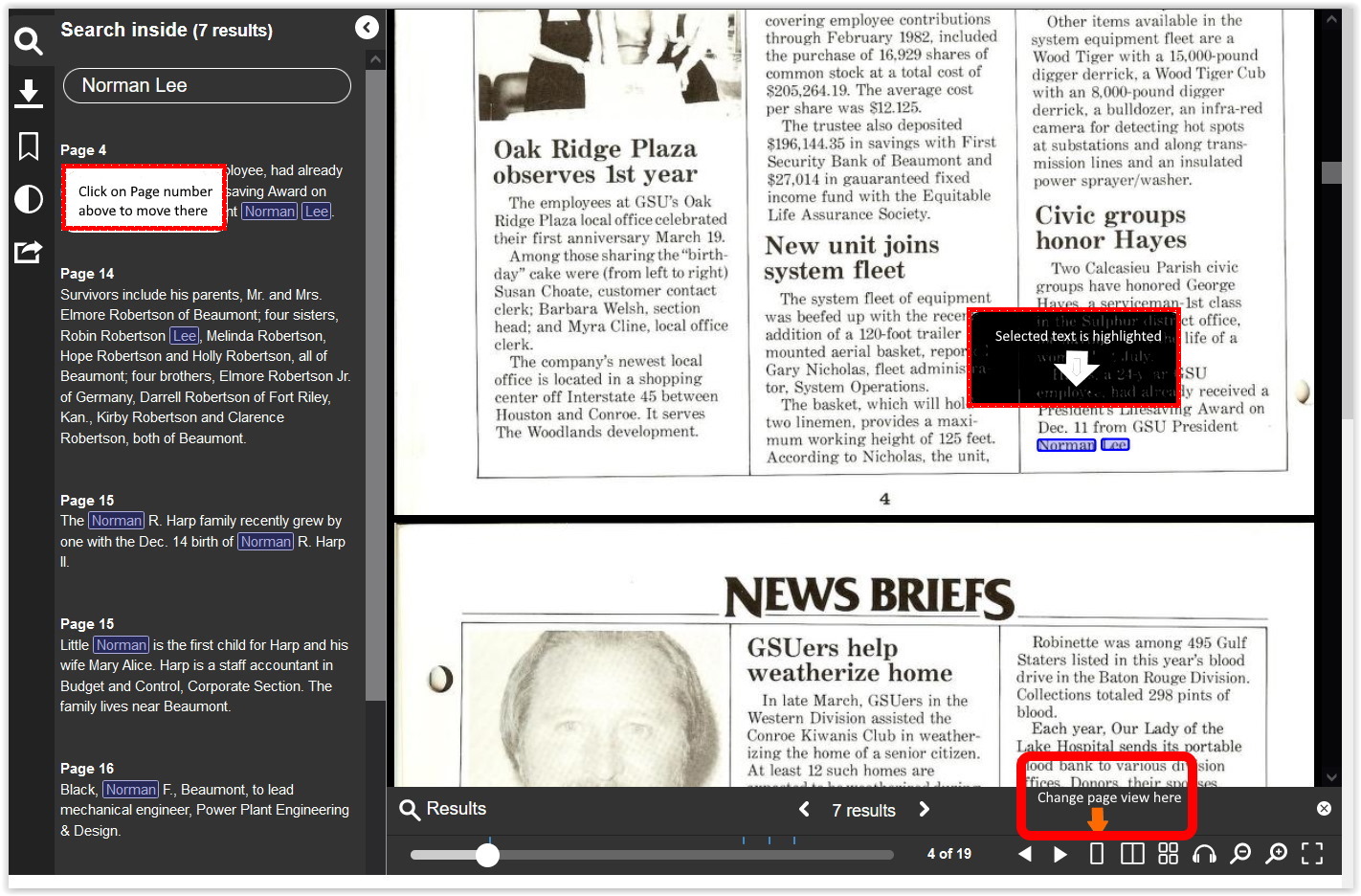
In the viewer for an issue:
Why did I do this?
When I started managing the Plain Talks Library site, I wished I could search the text of the issues. Back then, the software to convert the page images to text (OCR or Optical Characer Recognition) was a manual "one issue at a time" process. Afterwards, the PDF file would have doubled or tripled in size. It was not a good idea at that time.
Fast forward to 2022. I noticed comments somewhere about converting PDF files to searchable PDF files and the PDF files got smaller. That stirred up my interest again. I found the software that would make a PDF file searchable and smaller. It was still a "one at a time" process.
About the same time I ran across the Internet Archive web site. They have been archiving pages off the internet since 1999. I found out that you can upload PDFs to their site and they will convert it to searchable and archive it. They have something called a Collection. A searchable copy of the Plain Talks Library now exists on the Internet Archive site as the GSU Plain Talks Collection. I just had to upload them slowly so I didn't queue up too much work at one time for them. I automated the upload process. I just started that and watched for errors over the month it took to upload and process everything (470 issues).
The OCR process is not 100% accurate, but it is very good. To save money, some of the issues in the 1930's that were typewritten and printed on poor quality paper that allowed bleed through. Some of them didn't convert very well in spots. And there are problems in some issues when the paper slipped as it went through the scanner and distorted the letters.